如若轉載,請注明出處:http://www.rugus.cn/product/43.html
更新時間:2026-03-13 11:08:22
大數據的布局和思考 發力人工智能搶占先機
2021高考熱度最高專業,大數據分析告訴你
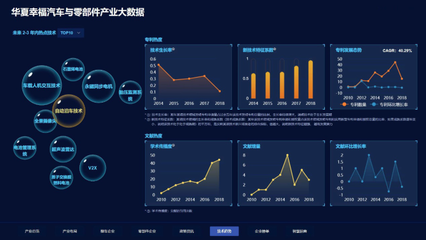
藍色大數據大氣企業可視化數據界面
健康大數據展示UI
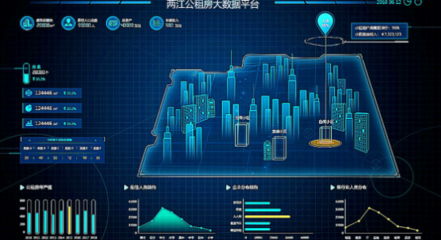
厲害了博拉:人臉識別、大數據為兩江新區公租房插上智慧翅膀
大數據背景圖
大數據加速滲透實體經濟
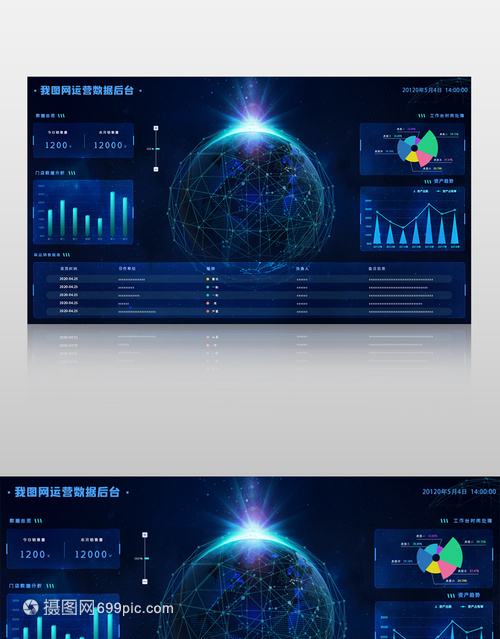
大屏設計-大數據綜合展示可視化平臺 - 瘋子110 - 博客園
大數據技術之SaCa DataViz 企業版 | 高性能大數據分析引擎
您知道什么叫大數據嗎?大數據面前,您一絲不掛
電話:13000000000
地址:廣州市從化區江埔街環市東路767號廣東水利電力職業技術學院水利電力工程中心313房自編12
Copyright © 2026 www.rugus.cn 大數據 廣州聞道科技有限公司 大數據 版權所有 Sitemap